语音合成的实质就是把文本转换成语音,很多云厂商都提供类似的服务,只需要调用 SDK 或 API 集成功能就可以。实现过程中仅需要考虑一个问题:云服务的响应时间,云服务自身比较繁忙,或者文本内容较长,都可能导致响应时间较长。
大多数据情况下,客户端每发送一次语音合成请求,服务端都会使用一个单独线程用于语音合成处理,客户端需要 同步 等待服务端处理完成。
考虑比较极端的场景:
- 客户端短时间内发送大量请求
- 云服务处理每个请求的响应时间较长
就可能会出现:
- 服务端线程长时间被占用,线程资源(数目)被耗尽
- 客户端 卡住
解决方案也很简单,就是客户端和服务端使用 异步 的协作方式,核心是 队列。
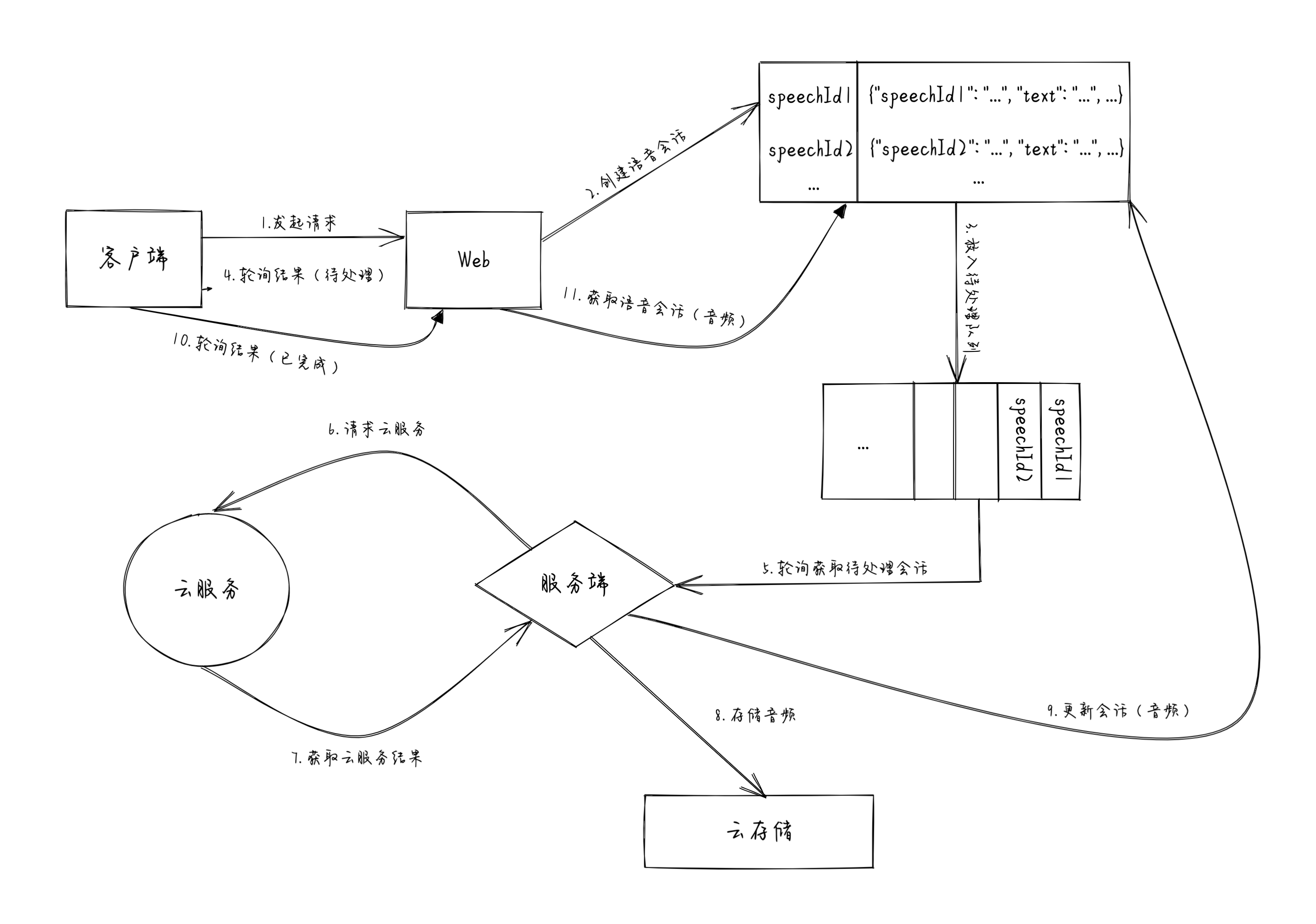
- 客户端向 Web 发起语音合成请求,请求中包含语音合成所需的文本内容和合成参数;
- Web 会为每一个语音合成请求创建一个语音合成会话,每一个语音合成会话包含语音合成会话 ID 和语音合成请求相关数据;
- Web 将语音合成会话 ID 保存到一个语音合成待处理队列;
这一步完成之后,Web 会将语音合成会话 ID 返回给客户端,客户端使用这个语音合成会话 ID 轮询获取语音合成结果。
- 客户端使用语音合成会话 ID 轮询请求语音合成结果,如果响应结果是待处理,表示该语音合成尚未完成,客户端需要等待若干时间之后,再次发起请求;如果响应结果是已完成(10),表示该语音合成已完成,响应结果中包含着语音合成结果;
- 服务端不断地轮询,从语音合成待处理队列获取需要处理的语音合成会话 ID,如果未获取到,表示没有语音合成需要处理,服务端等待若干时间之后,再次获取;如果获取到,表示有语音合成需要处理;
- 服务端根据获取到的语音合成会话 ID,查询语音合成会话中的语音合成请求相关数据,调用云服务,执行语音合成任务;
- 服务端等待云服务语音合成任务执行完成;
- 服务端将语音合成结果保存至云存储;
- 服务端根据语音合成会话 ID,将语音合成结果的云存储路径更新至语音合成会话中;
服务端的语音合成进程或线程数目可灵活控制。